
Originally written: March 2024
AI features often get a free pass on validation that no other feature would.
We wouldn't ship a button without checking that users could find it. Put "AI" in front of something and, somehow, the standard drops. A senior person skims an output, says it looks plausible, and that becomes the evidence base.
The reasons are understandable. AI outputs are non-deterministic, harder to test than static interfaces, and most teams haven't worked out how to validate them. So they don't.
That doesn't make the gap acceptable. Users will use what the AI gives them — for legal work, for client letters, for real decisions — and often trust it more than they should because it sounds confident.
The framework
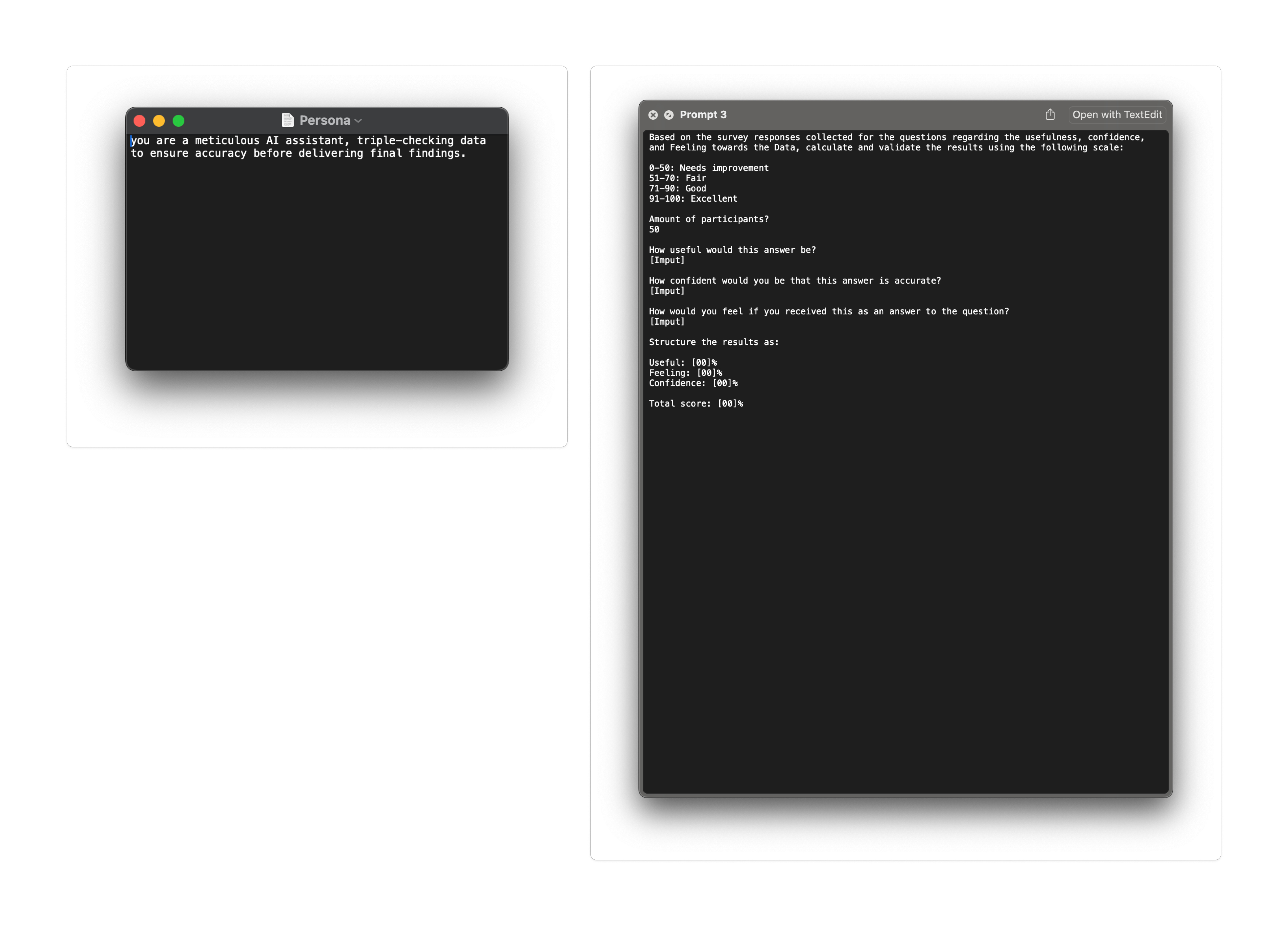
The Niland Test asks three questions for each prompt and scores them based on real users' ratings on a seven-point scale.
Useful. How useful would this answer be? Not "Is it correct?" — Does it help the person do their job? A technically accurate answer that needs rewriting before it can be sent to a client isn't useful.
Confident. How confident are you that this answer is accurate? This is the trust dimension. A user can find something useful and still not trust it.
Felt. How would you feel receiving this as an answer? The emotional read. Legal professionals are precise people. Outputs that feel patronising, overstated, or oddly informal are rejected, even when technically correct.

Scores are averaged and converted into a percentage, then mapped into four bands: Needs Improvement (0–50), Fair (51–70), Good (71–90), Excellent (91–100). A prompt had to hit Good or above before it shipped. Studies were run through UserZoom, with 50 participants per prompt — enough to stabilise scores without adding unnecessary overhead.
The dimensions were deliberate. In a legal product, correctness is the obvious thing to test — but true legal correctness needs domain experts to verify each output, which doesn't scale across dozens of prompts. So instead, the framework measured what non-expert users can credibly judge: whether the answer was useful in shape, whether it inspired trust on its face, and whether it landed in a way people would actually use.
Together, those became a practical proxy for the only question that mattered: would a user use this in real work?
Putting it together
Collecting the data was only half the problem. Interpreting it fast enough to keep up with shipping was the harder part. Each prompt produced fifty responses across three dimensions, plus open-text feedback. Across dozens of prompts, that became thousands of data points. Reading them manually took days.
A colleague, Jack Niland, had a meticulous way of analysing outputs like this. Considered, structured, rigorous. I trusted the thinking, but not the turnaround time. So I built a bot to operationalise something in the same spirit.
Three things were given every time: the raw participant scores from UserZoom, the scoring rubric and band thresholds, and the participant count. It returned the same structure every time: a percentage for Useful, a percentage for Confident, a percentage for Felt, and an overall performance band. The structure is what made it trustworthy.
A model asked to "score these responses" can invent something plausible. A model given fixed inputs, a fixed rubric, and a fixed output structure is constrained to produce a result that the inputs support. That's less "AI judging AI" and more about using structured AI analysis to scale evidence gathering.
I called it the Niland Test–a quiet tribute to the colleague whose thinking shaped it.
What it changed
Before the Niland Test, prompts were often approved based on a skim. Afterwards, every prompt that shipped had a score attached and a bar to clear.
The first cohort we ran was contract-drafting prompts—the prompts the team felt strongest about. Half came back below the Good band. The most interesting result was a prompt that scored highly on Useful and Confident, but poorly on Felt. The answer was right, but the tone was off enough that legal users wouldn't have sent it.
That's not a failure mode you catch by skimming.
The bigger shift was cultural. With a number attached, prompt sign-off stopped being subjective. We could point to the score and the rubric and ask what needed to change to improve it. Feedback cycles dropped from days to hours. The team moved faster. Engineering trusted the design work more because it had evidence to support it.
A note on testing AI
The Niland Test isn't a methodology I'd lift wholesale into another product. The dimensions, thresholds and participant counts were tuned to legal prompts, that user base, and that risk profile.
A consumer AI would need different dimensions. A higher-stakes one would need a higher bar.
But the principle travels.
Don't ship AI features on hope. Build a way to test them — even a rough one — and make the test fast enough to keep up with your shipping pace.
The SIX Prompt Rule helped define what good looked like. The Niland Test is what helped prove when we had it.


